
문자열 인코딩 방식 알아보기
인터넷은 UTF-8방식, 자바는 UTF-16으로 인코딩되어있다.
인코딩 방식이 변화한 흐름을 따라가면서 알아보자.
목차
ASCII 코드
✏️ 최상위 비트를 0으로 고정하고, 7bit를 사용하여 총 8bit (1byte)를 사용하는 인코딩 방식.영어만 사용할 경우, 영어(대/소문자 52개) + 수(10개) + 각종 문장부호들(60개) 합해서 총 120개가 필요하다. 즉, 총 7bit면(2^7=128) 충분히 표현할 수 있다.
단, 한글이나 유럽 등 다른 언어들은 1byte만으로는 나타내기 부족하다.
이후에 ASCII 코드에서는 고정한 ‘최상위 bit’를 사용하여 다른 언어들도 나타내는 방식이 나왔다. (Extended ASCII 코드, EUC 방식 등)
Extended ASCII 코드
Latin-1
ASCII 코드에서 사용하지 않았던 최상위bit를 활용한다. 총 8비트로 유럽에서 사용하는 문자까지 표현한다.
Extended Unix Code(EUC)
EUC-KR
ASCII 코드 범위의 문자들(영어,숫자 등)은 ASCII 코드와 똑같이 사용한다. (1byte 사용)
한글, 한자 등 ASCII로 표현할 수 없는 문자들은 2byte를 사용한다.
단, 이 방식도 표현하지 못하는 한글이 있어 이후에 CP949이 등장하게 된다. 현재는 CP949 방식을 많이 사용하고 있다.
Unicode
이전처럼 언어마다 다른 인코딩 방식은 불편한 사항들이 많았다. 한 어플리케이션안에 여러 언어가 섞여있거나, 나라별로 데이터를 주고 받을 때 불편함이 있었다. 이를 해결하기 위해 모든 언어의 국제 표준 규칙이 필요했고, Unicode가 나오게 되었다.
유니코드 평면
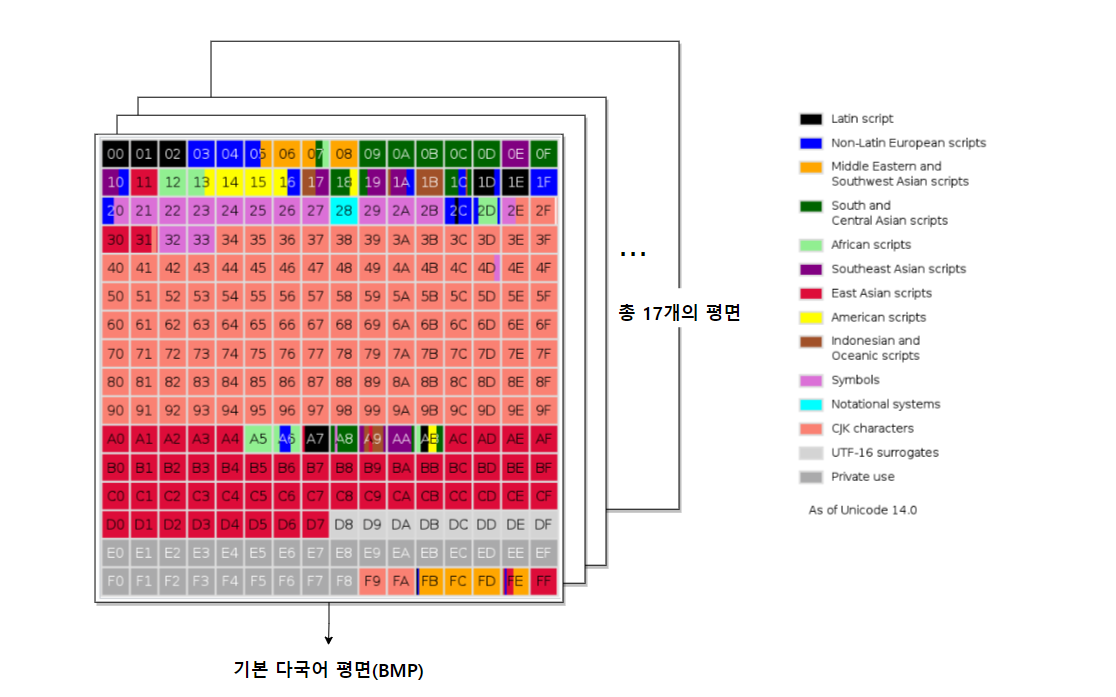
처음 표준화할 때는 16bit (2byte)으로 거의 모든 언어와 특수문자들을 처리할 수 있을거라 생각했다. 그러나 한자, 상형문자 등을 위한 공간이 더 필요했다. 이를 위해 16bit를 한 평면으로 하여 총 17개의 평면을 만들었다. 즉, 유니코드는 16bit * 17개의 평면으로 모든 언어를 나타내고 있다.
U+는 유니코드임을 나타내고, 평면 번호를 나타내는 16진수 숫자를 뒤에 붙여준다. 그리고 17개 중 어떤 평면인지 구분할 수 있는 숫자(16진수로 표현)를 앞에 붙여준다. 예를 들어, 평면 번호가 B000이고 1번 평면에 위치하면 U+1B000이다.
이때 첫 평면(0번 평면)을 기본 다국어 평면(BMP)이라 한다. 우리가 사용하는 거의 대부분의 문자들은 이 평면으로 모두 처리할 수 있다. 단, BMP는 평면 번호를 따로 붙이지 않는다.
UTF-32
유니코드의 모든 문자를 간단하게 표현할 수 있다. 그러나 한 글자가 4byte로 고정되어 용량을 많이 차지한다는 단점이 있다. 특히 1byte로 표현할 수 있는 문자들(아스키코드)도 고정적으로 4byte의 크기로 나타내게 되어 비효율적이다. 보다 효율적이게 처리하기 위해 가변적으로 문자마다 다른 byte수를 사용하는 방식이 나왔다. (UTF-16, UTF-8)
UTF-16
이전의 UTF-32 방식은 2byte로 표현할 수 있는 문자들도 고정적으로 4byte로 나타내어 비효율적이었다. UTF-16에서는 이를 개선하여 문자에 따라 유동적인 크기로 나타낸다. (2byte 또는 4byte)
우선 기본 다국어 평면(BMP)에 속한 문자는 한 문자당 16bit (2byte)로 인코딩된다. 이 범위의 문자들은 유니코드 값(평면 번호가 붙지 않은 유니코드값)을 그대로 사용하여 16bit로 변환해서 나타낸다.
그리고 그 외의 평면들에 속한 문자들은 서로게이트라는 방식을 사용하여 4byte로 나타낸다. 참고링크
단, UTF-16은 ASCII 코드와 호환되지 않는 다. 따라서 ASCII 코드와 호환되는 UTF-8이 나왔다.
UTF-8
UTF-8은 가변 길이를 지원하여 각 언어별로 최적화된 크기에 저장할 수 있도록 한다. 1바이트에서 3바이트까지 표현이 달라진다. 영문의 경우 1바이트로 나타내고 한글의 경우 3바이트로 나타낸다.
ASCII 문자 코드 값을 그대로 사용하여 호환된다. UTF-8 인코딩 방식의 부분집합이 ASCII라 할 수 있다.
문자에 따라서 1에서 4byte까지 사용하는 가변 길이 인코딩 방식이다. (영어는 1byte, 한글은 3byte)
인터넷에서 가장 많이 쓰이는 인코딩 방식이다. (ASCII 코드와의 호환성과 가변길이로 인한 공간효율성 때문!)
자바에서의 인코딩 방식
자바는 문자를 저장할 때, UTF-16 인코딩 방식을 사용한다. 그리고 자바에서 char 타입은 2byte의 공간을 사용한다.
유니코드의 BMP에 속하는 문자들(대부분의 언어)은 UTF-16에서 2byte를 사용하여 인코딩되기에 char형으로 1개 문자로 저장된다. 반면 유니코드의 BMP가 아닌 이외의 평면들에 속한 문자들(한자, 특수문자 등)은 UTF-16에서 4byte를 사용하기에 char형 2개 문자로 저장된다.
따라서 만약 아래와 같은 경우
char x = 'a'; (컴파일 O)
char y = '🧸'; (컴파일 X)
String z = "🧸"; (컴파일 O)
🧸의 경우 BMP에 속한 문자가 아니기 때문에, 4byte로 인코딩된다. 즉, char형 2글자이다. 따라서 홑따옴표로 감쌀 수 없다!
Reference
https://dev.epiloum.net/164
https://blog.naver.com/PostView.nhn?blogId=pjok1122&logNo=221505713248&categoryNo=29&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView
https://onlywis.tistory.com/2
Last updated